
Apakah itu Perceptron?
Perceptron ditemukan oleh Rosenblatt pada tahun 1958 [1]. Perceptron merupakan Artificial Neural Network (ANN) tanpa hidden layer, dimana input layer terhubung langsung dengan output layer. Perceptron merupakan salah satu algoritma linear, sehingga memiliki performa yang tidak cukup baik dalam menyelesaikan permasalah non-linear.
Secara umum perceptron model serupa dengan linear regresi model. Regresi dapat dimodelkan dengan formula:

dimana,

Sedangkan perceptron dapat dimodelkan dengan formula


dimana,
 = output \ function")
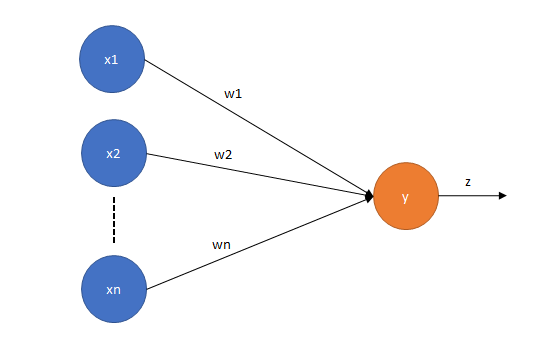
Dikarenakan model perceptron yang sederhana, saya menyarankan agar mempelajari perceptron terlebih dahulu sebelum mepelajari Multiple Layer Perceptron (MLP) atau ANN dengan hiden layer >= 1.
Pada postingan kali ini saya akan membahas mengenai perceptron dan bagaimana cara mentrain perceptron menggunakan back propagation. Di postingan ini, saya akan menggunakan Theano dalam mengimplementasi perceptron.
Training Perceptron Menggunakan BackPropagation
Tujuan utama dalam proses training adalah meminimalisir error atau perbedaan antara output yang diharapkan (desired output) dan output sebenarnya yang dihasilkan oleh perceptron (actual output). Dalam hal ini kita dapat menggunakan algoritma seperti backpropagation. Cara kerja algoritma backpropagation sendiri adalah dengan mengubah nilai weights pada sebuah perceptron secara iterative berdasarkan nilai error hingga nilai error mencapai batas tertentu. Secara umum terdapat tiga tahapan pada BackPropagation.
- Forward Propagation: Pada tahap ini input akan diberikan kepada perceptron, dap perceptron akan menghasilkan output berdasarkan input tersebut.
- Error Calculation: Perbedaan antara actual output dan desired output dikalkulasi menggunakan sebuah fungsi error (contoh: root mean square atau croos entropy)
- Backpropagation: Merubah nilai weight pada perceptron berdasarkan nilai error pada tahan ke dua.
Ok pada bagian ini saya akan menjabarkan secara singkat tentang ketiga tahapan diatas.
Forward Propagation
Tahap forward propagation adalah proses dimana perhitungan output perceptro berdsarkan input yang diberikan. Hal ini dapat diselesaikan dengan formula dibawah:
Untuk  = output \ function")

")
dimana
 = \dfrac{1} {1 + e ^ {-z}}")
 ^ {-2} = \dfrac{1}{1 + e ^ {-z}} \dfrac{e^{-z}}{1 + e^{-z}} = y(1 - y)")
Pada tutorial ini saya menggunakan fungsi Sigmoid sebagai fungsi keluaran perceptron dikarenakan nilai output yang saya harapkan adalah 0 atau 1.

Note:
- BP tidak dapat digunakan pada perceptron dengan binary threshold sebagai fungsi output, dikarenakan turunan binary threshold terhadap nilai z = 0 (
)

Error Calculation
Setelah mendapatakan output dari perceptron berdasarkan input yang diberikan, pada tahap error calculation perceptron akan dievaluasi “apakah output perceptron sesuai dengan output yang diharapkan atau tidak”. Untuk menghitung perbedaan antara actual output dan desired output dapat digunakan berbagai macam fungsi error seperti Squared Error, Root Mean Squared Error (RMSE), Cross Entropy, atau Cosine Proximity. Dalam tutorial ini saya akan menggunakan Squared Error(untuk memudahkan proses perhitungan BP)
Untuk

Squared error dari t dan y dapat dihitung menggunakan formula
^2")
dimana
^2 * -1 = - \Sigma (t_i - y_i)")
Note:
- Error fungsi juga dikenal dengan nama cost function dan objective function.
Back Propagation
Secara umum proses learning pada neural network adalah dengan mengubah nilai weights berdasarkan error yang dibuat network tersebut dalam memprediksi data yang diberikan. Proses learning pada network dapat diformulasikan dengan formula
dimana,

Kondisi:
- Jika output benar, maka
- Jika output salah (t =0 tetapi y = 1), maka
- Jika output salah (t =1 tetapi y = 0), maka



Pada backpropagation proses learning tidak berdasarkan desired output, namun berdasarkan turunan fungsi error 

 (t_i - y_i)")


Sehingga,


Note:
- Learning rate menentukan seberapa besar nilai weights akan berubah. Semakin kecil nilai learning rate, maka proses training akan semakin lama tapi perceptron akan dapat memahami lebih baik. Analogi (learning rate = tinggi = sistem kebut semalam, learning rate = kecil = belajar bertahap)
Implementasi menggunakan Theano
Pada tutorial ini saya akan menggunakan perceptron untuk menyelesaikan permasalahan gerbang logikal AND.
| INPUT | OUTPUT | |
| A | B | A AND B |
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Memodelkan perceptron dengan Theano
Langkah pertama dalam mengimplementasikan perceptron menggunakan Theano adalah mendefinisikan variable tensor.
|
1
2
3
4
|
#inputX = T.dmatrix('x')#desired outputt = T.ivector('t') |
Untuk variable weights dan bias, tidak hanya didefinisikan namun kita juga harus menginisialisasi nilai awal variable tersebut. Untuk weights saya menggunakan nilai random dengan limit ![[-4 \sqrt{\frac{6}{nInput + nOutput}}, 4 \sqrt{\frac{6}{nInput + nOutput}}]](https://s0.wp.com/latex.php?latex=%5B-4+%5Csqrt%7B%5Cfrac%7B6%7D%7BnInput+%2B+nOutput%7D%7D%2C+4+%5Csqrt%7B%5Cfrac%7B6%7D%7BnInput+%2B+nOutput%7D%7D%5D+&bg=%23ffffff&fg=%23000000&s=0 "[-4 \sqrt{\frac{6}{nInput + nOutput}}, 4 \sqrt{\frac{6}{nInput + nOutput}}]")


|
1
2
3
4
5
|
bound = 4 * (6./np.sqrt(nInput + nOutput))#weightsW = theano.shared(value=rng.uniform(low=-bound, high=bound, size=(nInput, nOutput)))#biasb = theano.shared(value= np.zeros(nOutput)) |
Pada tutorial ini saya menggunakan sigmoid sebagai activation function pada output layer. Pada theano terdapat build-sigmoid function sehingga kita tidak perlu membuat dari scratch.
|
1
2
|
#T.dot(a,b) = dot product dari variable a dan by = T.nnet.sigmoid(T.dot(X, W) + b) |
Implementasi Squared Error
Setelah berhasil memodelkan perceptron, langkah selanjutnya adalah dengan membuat fungsi untuk menghitung error. Saya menggunakan squared error untuk menhitung perbedaan actual output dan desired output.
|
1
2
|
def SE(t, y): return T.sum(T.power(t - y.T, 2))/2 |
Implementasi BackPropagation
Seperti dijelaskan sebelumnya, bahwa untuk mentrain perceptron menggunakan BackPropagation, nilai weights dan bias akan diubah berdasarkan derivative error function (cost function) terhadap variable yang bersangkutan. 

Pada Thenao, untuk menghitung derivative terhadap sebuah variable, kita dapat menggunakan fungsi T.grad().
|
1
2
3
4
5
|
cost = SE(t, y)#gradient cost function terhadap variable WgW = T.grad(cost, W)#gradient cost function terhadap variable bgB = T.grad(cost, b) |
Setela menghitung nilai

Implementasi formula diatas pada theano dapat dilakukan dengan mengexpresikan formula diatas pada sebuah variable
|
1
|
updates = [(W, W - learningRate * gW), (b, b - learningRate * gB)] |
(W, W – learningRate * gW) memiliki arti 
Wrap Everything
Langkah terakhir dalam mengimplementasikan perceptron pada Theano adalah dengan menyatukan model diatas pada sebuah fungsi. Pada tahap ini, kita akan mendefinisikan sebuah fungsi Theano yang akan menyatukan ekspresi – ekspresi diatas.
|
1
2
|
trainModel = theano.function(inputs=[X, t], outputs=cost, updates=updates)testModel = theano.function(inputs=[X], outputs=pred) |
trainModel adalah fungsi yang akan digunakan untuk mentrain perceptron, dimana input fungsi tersebut adalah X dan t (desired output), sedangkan outputnya adalah cost atau error function. Pada fungsi ini dijelaskan juga tentang variable yang akan diupdate setiap fungsi ini dijalankan.
testModel adalah fungsi yang akan digunakan untuk mentest perceptron, dimana input funsi tersebut adalah X dan outputnya adalah nilai prediksi terhadap input yang diberikan.
Train Perceptron
Untuk mentrain perceptron, kita hanya perlu memanggil fungsi trainModel, jika ingin mentrain perceptron sebanyak 100 iterasi kita hanya perlu memanggil fungsi tersebut sebanyak 100 kali. Hal tersebut dapat diimplementasikan dengan mudah menggunakan loop.
|
1
2
|
for i in range(100): err = trainModel(inputX, desiredOutput) |
Atau jika ingin mentrain model hingga error function dibawah batas tertentu kita dapat menggunakan while.
|
1
2
3
|
err = 1while err > 0.5 err = trainModel(inputX, desiredOutput) |

Note:
- Penggunakan error fungsi tergantung dengan permasalahan yang ingin dimodelkan dengan ANN, apakah itu regresi, binary-classification, atau multiclasses-classification
Full Code
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import theanoimport theano.tensor as Timport numpy as npdef SE(t, y):return T.sum(T.power(t - y.T, 2))/2inputX = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])desiredOutput = np.array([0, 0, 0, 1])rng = np.random.RandomState(5145022)nInput = 2nOutput = 1iterationStep = 1000learningRate = 0.1X = T.dmatrix('x')t = T.ivector('t')bound = 4 * (6./np.sqrt(nInput + nOutput))W = theano.shared(value=rng.uniform(low=-bound, high=bound, size=(nInput, nOutput)))b = theano.shared(value= np.zeros(nOutput))y = T.nnet.sigmoid(T.dot(X, W) + b)pred = y > 0.5cost = SE(t, y)gW = T.grad(cost, W)gB = T.grad(cost, b)updates = [(W, W - learningRate * gW), (b, b - learningRate * gB)]trainModel = theano.function(inputs=[X, t], outputs=cost, updates=updates)testModel = theano.function(inputs=[X], outputs=pred)err = 1errList = np.zeros(iterationStep)for i in range(iterationStep):err = trainModel(inputX, desiredOutput)errList[i] = errprint(testModel(inputX)) |
Referensi
- Rosenblatt, Frank. “The perceptron: A probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
- Glorot, Xavier, and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks.” Aistats. Vol. 9. 2010.